
Attention Mechanism and Transformers
Published:
Introduction
Transformer is a term that everyone also must understand first if they want to dive into Large Language Model, but I happened to read about LayoutLM, BERT term first. After that, I returned Transformer to understand how it works. Unlike the tasks in Computer Vision, for me, LLM is actually much more difficult to approach and takes a lot of time to read papers, mathematics understanding and code implementation.
In the blog, let’s learn about design, mathematical models and their applications. In the other blog on Harvard NLP also provides detail explanation with code implementation.
Model Architecture
Transformer model has an encoder-decoder structure:
Given a input sequence of symbol representations
\[X = (x_1, x_2, ..., x_n)\]The encoder will map X to sequence of countinuous representations
\[Z=(z_1, z_2, ..., z_n)\]Given $Z$, the decoder then generates an output sequence $Y=(y_1, y_2, …, y_m)$ of symbols of one element at a time. At each step the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next.
Next, we go to the detailed components of the architecture in Transformer.
![]()
Encoder
The encoder is composed of a stack $N=6$ identical layers. At each layer includes two sub-layer:
- Multi-Head Self-Attention and Add & Norm
- Feed Forward and Add & Norm
Decoder
The decoder is composed of a stack $N=6$ identical layers. In addition to the two sub-layers in each encoder layer, at each layer includes three sub-layer:
- Masked Multi-Head Self-Attention and Add & Norm
- Multi-Head Self-Attention and Add & Norm
- Feed Forward and Add & Norm
Furthermore, self-attention in sub-layer also modified to prevent positions from attending to subsequent positions. This masking, ensures that the predictions for position $i$ can depend only on the known outputs at positions less than $i$.
Add & Norm Layer
Add & Norm Layer is a component followed by layer normalization and the output of each sub-layer is:
\[LN(X + S(X))\]where $S(X)$ is the function implemented by the sub-layer itself, $LN$ is layer normalization.
Attention
Attention is function can be described mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. Assume that, the input consists of queries and keys of dimemsion $d_k$, and values of dimension $d_v$.
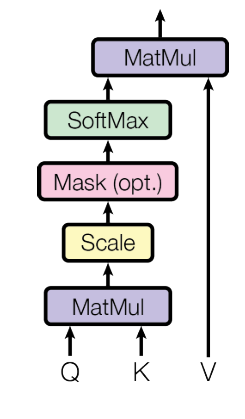
The output of Attention is computed by the Scaled Dot-Product Attention:
\[\text{Attention}(Q, K, V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V\]Code implementation:
def masked_softmax(X, valid_lens):
"""Perform softmax operation by masking elements on the last axis.
Defined in :numref:`sec_attention-scoring-functions`"""
# X: 3D tensor, valid_lens: 1D or 2D tensor
def _sequence_mask(X, valid_len, value=0):
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# On the last axis, replace masked elements with a very large negative
# value, whose exponentiation outputs 0
X = _sequence_mask(X.reshape(-1, shape[-1]), valid_lens, value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
class DotProductAttention(nn.Module):
"""Scaled dot product attention.
Defined in :numref:`subsec_batch_dot`"""
def __init__(self, dropout):
super().__init__()
self.dropout = nn.Dropout(dropout)
# Shape of queries: (batch_size, no. of queries, d)
# Shape of keys: (batch_size, no. of key-value pairs, d)
# Shape of values: (batch_size, no. of key-value pairs, value dimension)
# Shape of valid_lens: (batch_size,) or (batch_size, no. of queries)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# Swap the last two dimensions of keys with keys.transpose(1, 2)
scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
Multi-Head Attention
Instead of performing a single attention function, it allows the model to jointly attend to information from different representation subspaces at different positions. That perform the attention function in parallel.
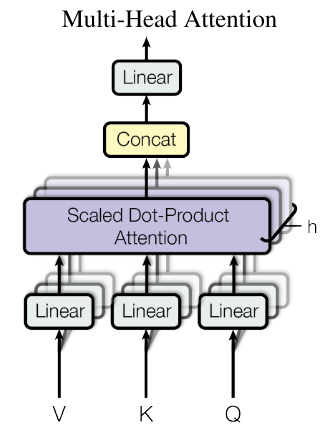
where
$\text{head}_i=\text{Attention}(QW_i^Q, KW_i^K, VW_i^V)$,
$W_i^Q \in R^{d_\text{model} \times d_k}, W_i^K \in R^{d_\text{model} \times d_k}, W_i^V \in R^{d_\text{model} \times d_v}, W^O \in R^{hd_v \times d_\text{model}}$
Code implementation:
class MultiHeadAttention(nn.Module):
"""Multi-head attention.
Defined in :numref:`sec_multihead-attention`"""
def __init__(self, num_hiddens, num_heads, dropout, bias=False, **kwargs):
super().__init__()
self.num_heads = num_heads
self.attention = DotProductAttention(dropout)
self.W_q = nn.LazyLinear(num_hiddens, bias=bias)
self.W_k = nn.LazyLinear(num_hiddens, bias=bias)
self.W_v = nn.LazyLinear(num_hiddens, bias=bias)
self.W_o = nn.LazyLinear(num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# Shape of queries, keys, or values:
# (batch_size, no. of queries or key-value pairs, num_hiddens)
# Shape of valid_lens: (batch_size,) or (batch_size, no. of queries)
# After transposing, shape of output queries, keys, or values:
# (batch_size * num_heads, no. of queries or key-value pairs,
# num_hiddens / num_heads)
queries = self.transpose_qkv(self.W_q(queries))
keys = self.transpose_qkv(self.W_k(keys))
values = self.transpose_qkv(self.W_v(values))
if valid_lens is not None:
# On axis 0, copy the first item (scalar or vector) for num_heads
# times, then copy the next item, and so on
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# Shape of output: (batch_size * num_heads, no. of queries,
# num_hiddens / num_heads)
output = self.attention(queries, keys, values, valid_lens)
# Shape of output_concat: (batch_size, no. of queries, num_hiddens)
output_concat = self.transpose_output(output)
return self.W_o(output_concat)
def transpose_qkv(self, X):
"""Transposition for parallel computation of multiple attention heads.
Defined in :numref:`sec_multihead-attention`"""
# Shape of input X: (batch_size, no. of queries or key-value pairs,
# num_hiddens). Shape of output X: (batch_size, no. of queries or
# key-value pairs, num_heads, num_hiddens / num_heads)
X = X.reshape(X.shape[0], X.shape[1], self.num_heads, -1)
# Shape of output X: (batch_size, num_heads, no. of queries or key-value
# pairs, num_hiddens / num_heads)
X = X.permute(0, 2, 1, 3)
# Shape of output: (batch_size * num_heads, no. of queries or key-value
# pairs, num_hiddens / num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(self, X):
"""Reverse the operation of transpose_qkv.
Defined in :numref:`sec_multihead-attention`"""
X = X.reshape(-1, self.num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
Position-wise Feed-Forward Networks
In addition to attention sub-layers, each of the layers in encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformation with a ReLu activation in between
\[FFN(X)=\text{max}(0, XW_1 + b_1)W_2 + b_2\]Code implementation:
class PositionWiseFFN(nn.Module):
"""The positionwise feed-forward network.
Defined in :numref:`sec_transformer`"""
def __init__(self, ffn_num_hiddens, ffn_num_outputs):
super().__init__()
self.dense1 = nn.LazyLinear(ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.LazyLinear(ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
Position Encoding
In order for the model to make use of the order of the sequence, we need to inject some information about the relative and absolute position of the tokens in the sequence called position encoding. The position encoding is embedding vector is directlly added to input embedding and they help the model determine the distance between different words in the sequence by using sine and cosine functions of different frequencies:
\[PE_{pos, 2i}=sin(pos/10000^{2i/d_\text{model}})\] \[PE_{pos, 2i+1}=cos(pos/10000^{2i/d_\text{model}})\]Code implementation:
class PositionalEncoding(nn.Module):
"""Positional encoding.
Defined in :numref:`sec_self-attention-and-positional-encoding`"""
def __init__(self, num_hiddens, dropout, max_len=1000):
super().__init__()
self.dropout = nn.Dropout(dropout)
# Create a long enough P
self.P = torch.zeros((1, max_len, num_hiddens))
X = torch.arange(max_len, dtype=torch.float32).reshape(
-1, 1) / torch.pow(10000, torch.arange(
0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)
self.P[:, :, 0::2] = torch.sin(X)
self.P[:, :, 1::2] = torch.cos(X)
def forward(self, X):
X = X + self.P[:, :X.shape[1], :].to(X.device)
return self.dropout(X)