
BERT: Combining the Best of Both Worlds
Published:
Introduction
From context-independent to context-sensitive
For both word2vec and GlobVe assign the same pretrained vector to the same word regardless of the context of the word (if any) Formally, a context-independent representation of any token $x$ is function $f(x)$ that only takes $x$ as its input.
For instance, the word have in context I have a pencil and I have lunch has completely different meanings; thus the same word may be assigned different representations depending on contexts.
Besides, a context-sensitive representation of token $x$ is a function $f(x, c(x))$ depending on both $x$ and its context $c(x)$.
For example, the previous apporoaches (ELMO) take the entire sequence as input and is a function that assign a representations to each word from the input sequence. However, the existing supervised model is specifically customized for a given task. Leveraging different best models for different tasks at that time.
From Task-Specific to Task-Agnostic
Basically, ELMO still hings on a task-specific architecture. It is practically non-trivial to scraft a specific architecture for every natural language processing tasks.
GPT model represents an effort in designing a general task-agnostic model for context-sensitive representations. However, GPT only looks forward (left-to-right). For instance, a context-sensitive representation of token $x$ is a function $f(x, c_1(x), c_2(x))$, GPT will return the same representation for token $x$, though it has different meanings.
Combining the best of both worlds
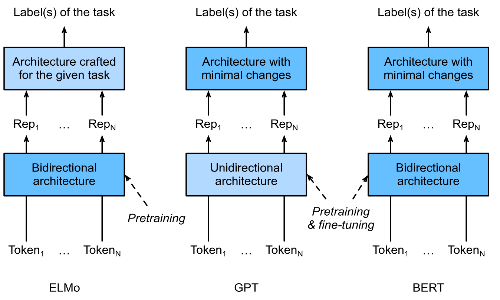
As we have seen, ELMo encodes context bidirectionally but only applies task-specific architecture; while GPT is task-agnostic but encodes context left-to-right. Combining the best of both worlds, BERT encodes context bidirectionally and requiries minimal archtecture changes for a wide range of NLP tasks:
- Single text classification (e.g., setimment analysis)
- Text pair classification (e.g., nature language inference)
- Question Answering
- Text Tagging (e.g., NER)
Bidirectionally Encoder Representations from Transformer (BERT)
Input Representation
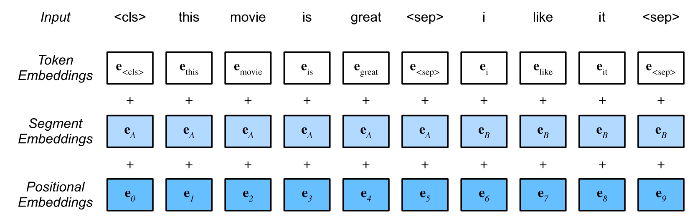
BERT input sequence is concatenation of $<$cls$>$, tokens of the first text sequence, $<$sep$>$, tokens of the second text sequence, $<$sep$>$
BERT chooses the Transformer encoder as it bidrectional architecture. The different from the original Transformer encoder, BERT use segment embeddings and learnable positional embeddings. Finally, the embeddings of the BERT input sequence are the sum of the tokens embeddings, segment embedding and positional embedding.
Pretraining and Finetuning Task
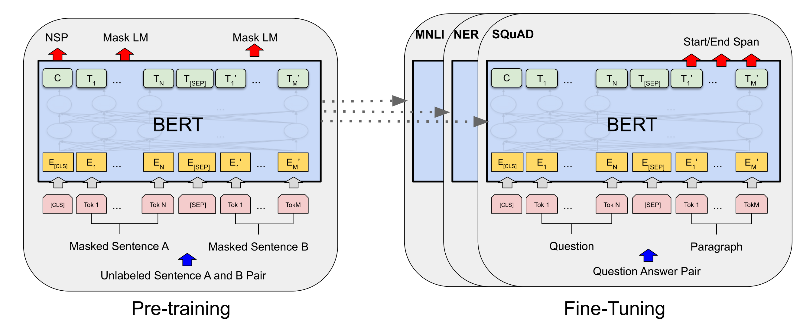
Pretraining task: Masked Language Model(Masked LM)
To encode context bidirectionally for representing each token, BERT randomly masks tokens and use tokens from the bidirectional centext to predict the masked tokens as a unsupervised problem.
In this pretraining task, 15% of tokens will be selected at random as masked tokens for prediction. To predict masked tokens without cheating by using label, one straightforword appoarch is to always replace it with special $<$mask$>$ token in BERT input sequence.
However, in this finetuning task, the specical $<$mask$>$ token will never appear because we need the output clearly. To avoid such as mismatch between pretraining and fine-tuning, if token is masked for prediction, in the input it will be replaced with:
- A specical $<$mask$>$ token for 80% of the time in the total of 15% tokens will be selected and replaced.
- A random token for 10% of the time in the total of 15% tokens will be selected to replace the word with a random word.
- The unchanged label token for 10% the time in the total of tokens will be selected.
Pretraining Task - Next Sequence Prediction
Masked LM is able to encode the bidirectional context for representing words, it does not model the logical relationship between a pair of sequences. To understand the sentence relationships, BERT considers a binary classification task namely are Next Sequence Prediction.
Specifically, when choosing sentence $A$ and $B$ for pretraining example, 50% of the time $B$ is the actual next sequence that follow $A$, and 50% of the time it is a random sentence from the corpus.
Fine-tuning task
During fine-tuning, the minimal architecture changes required by BERT across different applications are the extra fully connected layers, during supervised learning of a downstream task application, parameters of extra layers are learned from scratch while all the parameters in the pretraining task are fine-tuned end-to-end. The below is fine-tuning BERT for sequence-level (single text classification, text pair classification) and token-level (text tagging, question and answering) application.
Single text classification takes a single text sequence as input and outputs its classification result. For instance, “I should study.” is acceptable (label 1) but “I should studying.” is not (label 0).
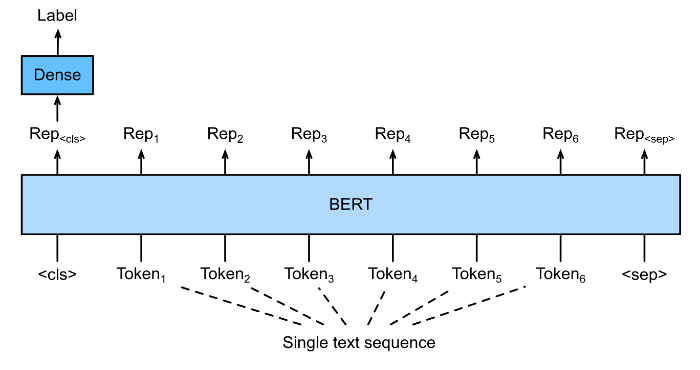
Single Text Classification
Taking a pair of text as input but outputting a continuous value, semantic textual similarity is a popular text pair regression task. This task measures semantic similarity of sentences.
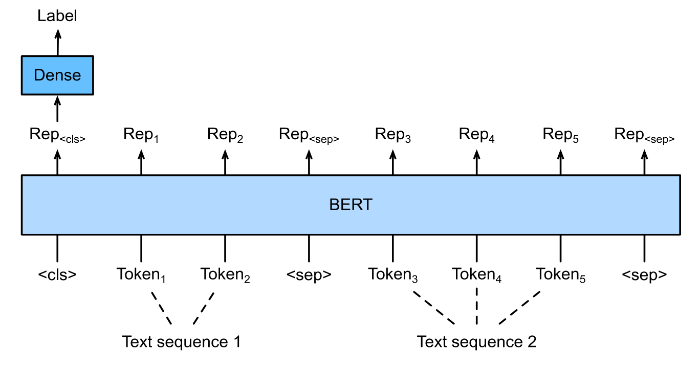
Text Pairs Classification
Text tagging, where each token is assigned a label. For example, according to the Penn Treebank II tag set, the sentence “John Smith ’s car is new” should be tagged as “NNP (noun, proper singular) NNP POS (possessive ending) NN (noun, singular or mass) VB (verb, base form) JJ (adjective)”.
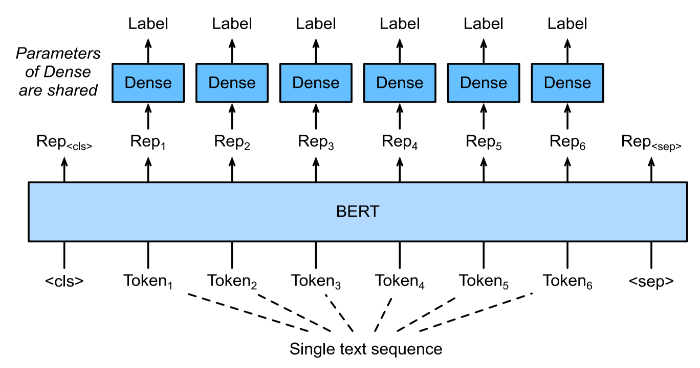
Text Tagging
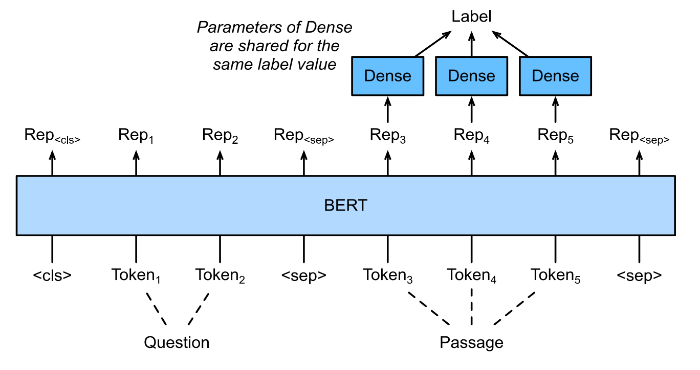
Question and Answering