
Export Pytorch model with ONNX Runtime to inference
Published:
Introduction
While understanding ONNX, a relatively new concept for me, required significant effort, it’s crucial to grasp the features, tools, and libraries involved in deploying an implemented model across diverse platforms and devices for real-world applications.
1. What is ONNX?
ONNX (Open Neural Exchange) can be represented as a graph that show step-by-step how to transform the features (mathematical functions/operators) to get a prediction. That’s why a machine-learning model implemented with ONNX is often referenced as an ONNX graph.
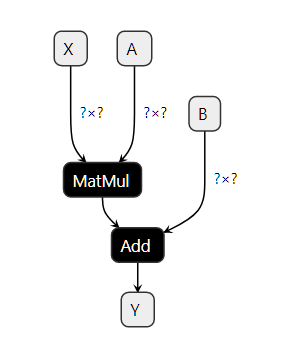
With ONNX operators, it ensures that predictions are equal or at least very close to th expected predictions computed with original model by using API.
Machine learning libraries usually have their own design. That’s why there exists a specific converting library for each of them.
- sklearn-onnx: converts models from scikit-learn,
- tensorflow-onnx: converts models from tensorflow,
- onnxmltools: converts models from lightgbm, xgboost, pyspark, libsvm
- torch.onnx: converts model from pytorch.
2. ONNX Runtime Python Inference
ONNX Runtime provides an easy way to run machine learned models with high performance on CPU, GPU, TensorRT, etc without dependencies on the training framework.
I utilized the PyTorch-trained CRNN model from this repository to convert and execute it in ONNX format using the Python API.
Convert to ONNX format
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
class Exporter:
def __init__(self, args):
# configurations argument
self.args = args
# Load character to label id mapping
__, self.id2char = map_char2id()
# Load Pytorch model
self.model = CRNN(len(self.id2char)+1)
self.model.load_state_dict(torch.load(self.args.model_path, map_location=self.args.device)['model'])
# Define input example
self.sample = torch.randn(size=cfg['Train']['dataset']['transforms']['image_shape']).unsqueeze(0).to(self.args.device)
self.model.to(self.args.device)
self.model.eval()
def export_onnx(self):
import onnx
print(f'Starting export with onnx {onnx.__version__}...')
# Define path to save model
f = str(self.args.model_path).replace('.pth', f'.onnx')
output_names = ['output0']
# Export model
torch.onnx.export(
self.model,
self.sample,
f,
verbose=False,
do_constant_folding=True,
input_names=['images'],
output_names=output_names,
dynamic_axes=None
)
model_onnx = onnx.load(f)
# Save model
onnx.save(model_onnx, f)
return f
Load and run the model using ONNX Runtime
Execution provider contains the set of kernels for a specific execution target (CPU, GPU, IoT etc). By default, ONNX Runtime always places intput and output on CPU In this example, I run model on CUDA supported in here
class Predictor:
def __init__(self, args) -> None:
self.args = args
self.load_exported_model()
def load_onnx_model(self):
print("Loading model for onnx inference...")
w = str(self.args.model_path).split('.pth')[0] + '.onnx'
import onnxruntime
providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']
self.session = onnxruntime.InferenceSession(w, providers=providers)
self.binding = self.session.io_binding()
def predict(self, img):
img = img.contiguous()
self.binding.bind_input(
name=self.session.get_inputs()[0].name,
device_type=self.args.device,
device_id=0,
element_type=np.float32,
shape=tuple(img.shape),
buffer_ptr=img.data_ptr(),
)
out_shape = [26, 1, 37]
out = torch.empty(out_shape, dtype=torch.float32, device='cuda:0').contiguous()
self.binding.bind_output(
name=self.session.get_outputs()[0].name,
device_type=self.args.device,
device_id=0,
element_type=np.float32,
shape=tuple(out.shape),
buffer_ptr=out.data_ptr(),
)
self.session.run_with_iobinding(self.binding)
# Can need to post processing here to get the final output ...
return out