
Everything You Need To Know About Implementation of CRNN Algorithm
Published:
Introduction
Text Recognition is a subtask of OCR, aimed at recognizing the content of one specific area. In the two-stage method of OCR, it comes after text detection to convert an image into a text. In this post, I will brifely give a high-level description of everything you need to know about the Pytorch’s implementation of CRNN Text Recognition algorithm as described on the paper.
How does CRNN works
The main contribution of this paper is a novel neural network model, it is specifically designed for recognizing sequence-like objects in images. Unlike general object recognition, such as object classification, object detection using DCNN models to operate on inputs and outputs with fixed dimensions, and thus are incapable of producing a variable-length label sequence.
For sequence-like objects, CRNN is designed to benifit advantages over conventional neural network models:
- It can be directly learned from sequence labels (for instance, words), requiring no detailed annotations (for instance, characters).
- It has properties of DCNN on leanring informative representations directly from image data.
- It also has properties of RNN, being able to produce a sequence of labels.
- It is uncontrained to the lengths of sequence-like objects, requiring only height normalization in both training and testing phases.
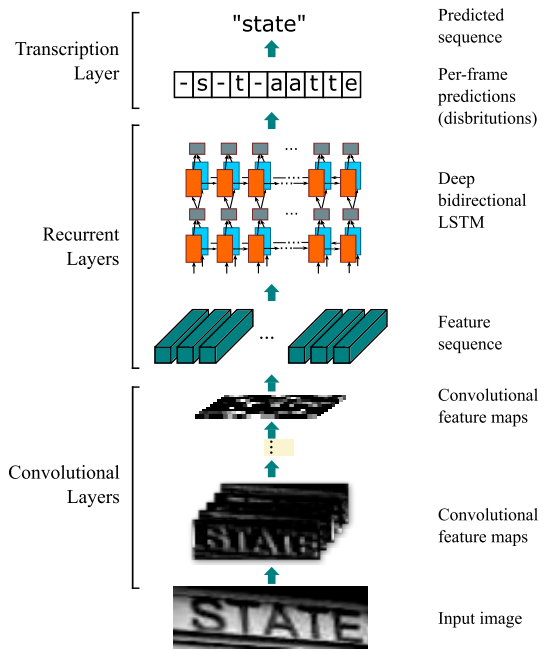
The CRNN algorithm
This section describes components of CRNN and how to the algorithm works
Feature Sequence Extraction
To simplify the input for RNN, input image will pass forward a CNN model was removed fully connected layer to get feature maps that have the same height. The sequence vector is extracted from feature maps by the convolutional layers.
from torchsummary import summary
print(summary(backbone, (3, 32, 100)))
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
├─Conv2d: 1-1 [-1, 64, 32, 100] 1,792
├─ReLU: 1-2 [-1, 64, 32, 100] --
├─MaxPool2d: 1-3 [-1, 64, 16, 50] --
├─Conv2d: 1-4 [-1, 128, 16, 50] 73,856
├─ReLU: 1-5 [-1, 128, 16, 50] --
├─MaxPool2d: 1-6 [-1, 128, 8, 25] --
├─Conv2d: 1-7 [-1, 256, 8, 25] 294,912
├─BatchNorm2d: 1-8 [-1, 256, 8, 25] 512
├─ReLU: 1-9 [-1, 256, 8, 25] --
├─Conv2d: 1-10 [-1, 256, 8, 25] 590,080
├─ReLU: 1-11 [-1, 256, 8, 25] --
├─MaxPool2d: 1-12 [-1, 256, 4, 26] --
├─Conv2d: 1-13 [-1, 512, 4, 26] 1,179,648
├─BatchNorm2d: 1-14 [-1, 512, 4, 26] 1,024
├─ReLU: 1-15 [-1, 512, 4, 26] --
├─Conv2d: 1-16 [-1, 512, 4, 26] 2,359,808
├─ReLU: 1-17 [-1, 512, 4, 26] --
├─MaxPool2d: 1-18 [-1, 512, 2, 27] --
├─Conv2d: 1-19 [-1, 512, 1, 26] 1,048,576
├─BatchNorm2d: 1-20 [-1, 512, 1, 26] 1,024
├─ReLU: 1-21 [-1, 512, 1, 26] --
==========================================================================================
Total params: 5,551,232
Trainable params: 5,551,232
Non-trainable params: 0
Total mult-adds (M): 636.77
==========================================================================================
Input size (MB): 0.04
Forward/backward pass size (MB): 4.94
Params size (MB): 21.18
Estimated Total Size (MB): 26.15
==========================================================================================
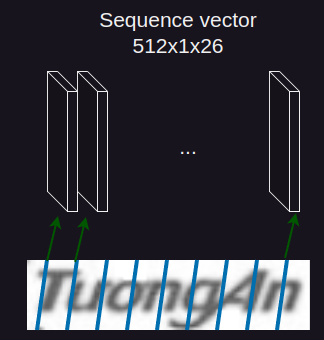
As above backbone summary, the sequence vector has dimension is (512, 1, 26). I will explain detail mechanism:
(512, 1, 26)corresponding to (channels, height, width) of sequence vector.- Why need to value
1of height?: this is mentioned in paper, it is height normalization in both training and testing phase.
Sequence Labeling
The sequence vector is converted into a vector input $(x_1, x_2, …, x_T), \forall x_i \in \mathbb{R}^{26 \times 512}$ with corresponding labels $(y_1, y_2, …, y_T)$ and sends it to the LSTM network (source code).
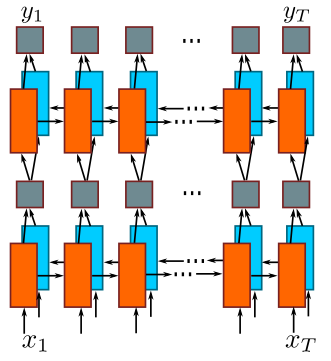
Transcription Layer
Transcription is to find the label sequence with hightest conditional probability on per-frame predictions (outputs from LSTM model) by using CTC algorithm and remove the repeat labels and blanks.
The CTC algorithm can assign a probability for any output $Y$ and input $X$. The easy way to understand it is how CTC thinks about alignments between inputs and outputs as below:

Alignment algorithm
However, this above approach has problems:
- There is no certainty between input and output when removing the repeat labels, i.e, sooooon $\rightarrow$ son, toooo $\rightarrow$ to.
- In speech recognition, the input can have strethes of silence with no corresponding output.
To get around these problems, CTC use a new character to the set of allowed outputs $\epsilon$ (blank character). The $\epsilon$ character doesn’t correspond to anything and is simply removed from the output. The below figure describes steps that how to map to $Y$ (Target $Y$ is TUONGANN) after merging repeats and removing blank characters.
![]()
CTC loss function
How to model CTC algorithm mathematically? The CTC algorithm go from probabilities at each time-step to the probability of an output sequence.
The RNN network gives $p_t(a\vert X)$ - a distribution over the outputs $\lbrace t, u, o, n, g, a, \epsilon\rbrace$ for each input step.
With the per time-step output distribution, the probability of single alignment is computed:
\[\prod_{t=1}^{T}p_t(a_t | X)\]Then, use many-to-one map $B$ to remove repeat and blank characters. The conditional probability of a labeling $Y$ is as the sum of probabilities of all $p_t$ that are mapped by $B$:
The CTC loss function is optimized with respect to the per time-step output probabilities. For a training set $D$, the model’s paramters are tuned to minimize the negative log likelihood
\[O=\sum_{(X,Y) \in D} - log \space p(Y|X)\]The CTC loss and enhanced CTC loss are implemented from source code